



2. Caratteristiche intrinseche degli strumenti informatici
Sistemi aperti, sistemi centralizzati e proprietari, integrazione delle informazioni e delle funzioni: si tratta di questioni che riguardano non solo e non tanto il problema dell'automazione degli archivi storici, quanto - più in generale e con un impatto futuro assai rilevante - la creazione di sistemi informativi integrati per la gestone dei documenti, compresi gli archivi correnti.
Gli sviluppi tecnologici più recenti e la diffusione di standard per la comunicazione delle informazioni ha reso questa alternativa meno esclusiva e drammatica: la creazione di reti condivise e la capacità di ricevere e distribuire informazioni richiedono, però, scelte tecnologiche precise e, soprattutto, preventive valutazioni di natura generale nella costruzione del sistema, che tengano conto non solo delle risorse finanziarie e umane disponibili, ma anche degli sviluppi possibili e identificabili dell'applicazione.
formati di scambio che accanto alla salvaguardia dei dati consentano di conservarne anche le relazioni reciproche
integrazione di funzioni e attività diverse nella gestione delle diverse fasi di vita dei documenti in archivi tradizionali e elettronici
interconnessione attiva tra organismi e istituzioni diverse
Ogni scelta presenta limiti e vantaggi che devono essere considerati e valutati:
Nella costruzione di un sistema centralizzato la normalizzazione e, quindi, l'affidabilità dei dati sono obiettivi meno incerti, anche se lo sforzo di costruzione iniziale è molto più complesso per la necessità di predisporre per tempo ogni possibile variante, prevedendo in dettaglio sia le modalità di rilevazione che le tabelle necessarie a dare uniformità e leggibilità alle informazioni raccolte. Il futuro ed eventuale collegamento al sistema implica l'adesione sostanzialmente passiva alle norme predisposte e codificate dall'organismo promotore e ad una struttura informativa predefinita e non modificabile.
Nel caso di sistemi aperti, flessibili e integrati, il vantaggio di non scegliere strutture e formati rigidi ha la sua contropartita nella difficoltà di basare l'acquisizione dei dati su criteri e principi rigorosamente fondati e omogenei. La soluzione in queste condizioni non può che rinvenirsi nella faticosa elaborazione di standard comuni tra gli operatori, tanto più efficaci, quanto più consapevolmente condivisi.
| CENTRAL-MAINFRAME-AND-MASTER-DATABASE-BUSINESS MODEL | DISTRIBUTED-KNOWLEDGE-AND-UNSTRUCTURED INFORMATION MODEL | ||
| | un mercato ampio e stabile, dominato da una produzione di massa, basato sul principio delle economie di scala | un mercato fortemente fragmentato, caratterizzato da una grande diversità di prodotti | |
| | una sostanziale stabilità dell'investimento iniziale e dei prodotti hw/sw per un cospicuo periodo di tempo | una continua e veloce sostituzione degli investimenti e una diversificazione dei prodotti | |
| | una concentrazione delle competenze di disegno e gestione del sistema al vertice dell'organizzazione e un forte controllo delle strutture operative articolate gerarchicamente | una distribuzione del controllo e delle competenze di disegno e organizzazione delle base dati sulla pluralità dei gruppi e delle organizzazioni interessate | |
| | ad un ampliamento della base informativa e ad una continua ricerca di efficienza | ad una moltiplicazione dei fornitori di informazioni, all'accrescimento e alla specializzazione del contenuto informativo |
Lo sviluppo recente di reti eterogenee e di basi informative complesse e distribuite ha favorito lo sforzo verso la definizione di standard di comunicazione indipendenti da sistemi operativi e piattaforme hardware e compatibili con una pluralità di strutture organizzative delle informazioni scambiate, come SGML, Standard Generalized Markup Language.
SGML è uno standard ISO per operare un interscambio dinamico di informazioni strutturabili (documenti). SGML consente di descrivere le caratteristiche di documenti complessi senza ricorrere a standard proprietari di singoli produttori di software: un documento creato o convertito in formato SGML può, quindi, essere esportato verso altri sistemi mantenendo tutti i propri attributi e le caratteristiche formali.
Allo stesso modo è possibile descrivere (mark up) la struttura del documento, l'organizzazione logica delle sue parti costituenti, in modo che la descrizione non sia comunque persa nello scambio con sistemi dissimili, consentendo, cosi, che lo stesso documento sia ricostruito in qualsiasi altro formato.
Basandosi su un puro formato ASCII, ogni text-retrieval è in grado di indicizzare, cercare e ritrovare un documento SGML, indipendentemente dal software utilizzato per generarlo.
L'architettura del sistema
Il sistema attualmente in uso è costituito di componenti di larga diffusione (PC DOS-Windows), in modo da garantirne la massima esportabilità, totale o parziale; ma allo stesso tempo è assicurata la migrazione verso sistemi più potenti (UNIX).
La configurazione attuale è rappresentata da una rete Novell Netware 3,12 sulla quale sono attive due stazioni di acquisizione e consultazione e un sistema ottico per l'archiviazione delle immagini, collegati ad un file server.
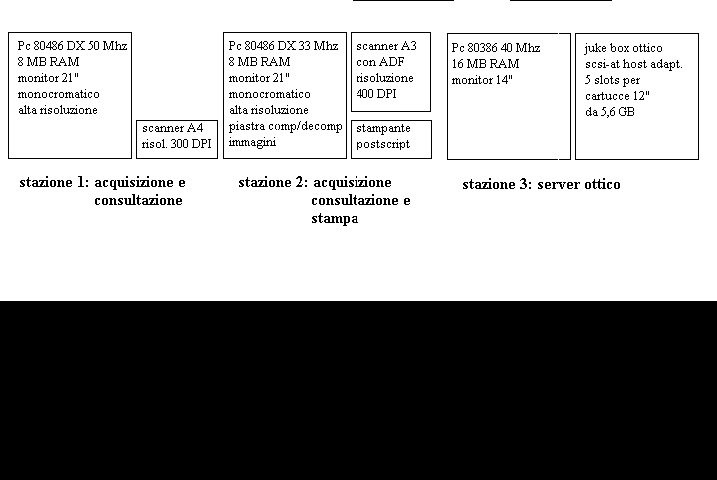
Il sistema così configurato è in grado di assicurare la memorizzazione e la consultazione immediata dell'intero fondo in lavorazione, sia per quanto riguarda la base informativa che la banca dati immagini.
In particolare, il drive ottico consente una capacità complessiva di 28 GB. Attualmente su una banca dati immagini di circa 100.000 pagine, lo spazio occupato è di circa 2,6 GB per altrettante immagini TIFF (Tagged Interchange File Format) compresse secondo gli standard fissati dal CCITT (International Telegraph & Telephone Consultative Committee) Gruppo 3 o 4, per un'occupazione media a pagina di 26 KB. La consistenza dell'intero fondo Archivio storico Iri è stimata in circa 800.000 fogli per un'occupazione totale di 21-22 GB.
I tempi di accesso alla singola immagine variano tra i 5-6 secondi sulla stessa cartuccia e gli 11 secondi compresi il cambio di cartuccia.
La soluzione software
L'ambiente di sviluppo software prodotto dalla 3D Informatica di Bologna
1. utilizza un'architettura di Information Retrieval che permette modalità di ricerca e tempi di risposta particolarmente efficienti;
2. integra tecniche di database relazionale per l'impostazione delle strutture informative e l'accesso ai dati;
3. consente una gestione di immagini integrata nella base dati con funzioni di compressione e decompressione sia hardware che software, utilizzo di dischi ottici removibili, visualizzazione e stampa immediata;
4. offre strumenti per la creazione e l'utilizzo di un tesauro gerarchico adattabileal proprio campo applicativo mediante definizione delle relazioni tra termini e concetti, del loro significato e dominio d'uso.
Il software è costruito secondo un'architettura client-server: tipicamente gestisce il colloquio tra il server di retrieval e i diversi moduli di interfaccia, per il processamento dei dati, per la gestione delle immagini e per l'accesso ai dizionari di campo e ai tesauri.

modularità funzionale e capacità di ampliamento
compatibilità con sistemi operativi e piattaforme diversi
gestione della multiutenza in scrittura e lettura della banca dati
colloquio con applicativi software diversi (WordProcessor, OCR)
interfaccia user-friendly a finestre
impostazione MDI (Multiple Document Interface)
uso della tecnologia ODBC (Open Data Base Connectivity) per il collegamento a base dati esterne
La struttura dei dati
La base di dati segue un modello reticolare, che consente di privilegiare l'efficienza nei tempi di ricerca e indicizzazione anche con volumi di dati considerevoli rispetto alla maggiore programmabilità ed attitudine alle transazioni di un database di tipo relazionale. Ogni singola tabella (tipologia di oggetti) raggruppa un sottoinsieme di attributi o campi, in grado di definire l'oggetto descritto.
In ogni tabella è possibile posizionare sia campi strutturati che più campi a testo libero: ogni campo fa riferimento a un proprio dizionario, costruito secondo le caratteristiche definite per il singolo attributo (insieme dei caratteri di separazione delle parole, elenco delle parole da non indicizzare perché non rilevanti, ecc.); è altresì possibile indirizzare il contenuto di più campi su un unico dizionario.
L'organizzazione gerarchica
Il sistema consente la definizione di legami gerarchici tra i record in maniera dinamica, operando un collegamento di tipo logico (padre, figlio, fratello) tra le schede. È possibile consultare l'indice gerarchico in maniera selettiva, aprendo i collegamenti che interessano.
Il sistema consente pienamente la ripetizione indefinita o il salto di livelli, in quanto queste relazioni sono indipendenti dal contenuto informativo. Sono quindi anche possibili procedure di manutenzione dell'indice gerarchico, come inserimenti di nuovi livelli, riorganizzazione o spostamenti di rami o di singoli record.
Le modalità di ricerca
Il sistema prevede due modalità di interrogazione: una interattiva o guidata, utilizzando una specifica maschera video di ricerca, attraverso cui è possibile accedere ai diversi dizionari di campo; una seconda libera, tramite la quale la presenza di una generica chiave di ricerca in linguaggio libero è verificata sull'intera banca dati indipendentemente dalla posizione delle informazioni.
La fase di ricerca si avvale del sistem a «liste invertite»: la lista dei riferimenti ai documenti trovati viene salvata su file temporaneo assieme alle parole chiave estratte per consentire al modulo client una segnalazione evidenziata delle parole ricercate all'interno dei documenti.
La ricerca può avvenire secondo diverse modalità e con diverse funzionalità:
- utilizzo di caratteri "jolly", operatori booleani (e, o, non), parentesi;
- ricerca estesa a parole ricollegabili a quelle presenti nel quesito in base alla coniugazione (singolare/plurale, maschile/femminile) o per somiglianza (uno o più caratteri diversi, cioè inseriti, rimossi o sostituiti);
- ricerca di parole contigue, stabilendo un parametro di vicinanza, di ordine e di contesto;
- utilizzo del tesauro per la ricerca di sinonimi e termini collegati;
- ricerca probabilistica dei documenti che contengono il maggior numero possibile di parole presenti nel quesito;
- ricerca per somiglianza dei documenti aventi il maggior numero di parole in comune con il documento evidenziato, attribuendo un peso ai termini secondo la loro rilevanza nel documento di partenza e la frequenza su tutti i documenti;
- raffinamento successivo della query;
- memorizzazione delle ricerche effettuate da ciascun utente;
- selezione dei risultati in «fascicoli» personali.
La navigazione ipertestuale
Il sistema dispone di un insieme di strumenti per creare dei legami "soggettivi" persistenti tra i documenti, basati su percorsi logici individuati dall'utente che consulta la banca dati: una volta tracciati i collegamenti tra documenti e immagini, sarà possibile navigare su queste "rotte logiche" lungo tutto l'archivio.
Il collegamento remoto
Il sistema consente un'ampia apertura verso le interrogazioni a distanza. È innanzitutto possibile interrogare la banca dati tramite un normale PC collegato alla rete telefonica senza bisogno di disporre di software specifico oltre quello di comunicazione.
Una più ampia e generalizzata strada di apertura e scambio di informazioni è stata realizzata attraverso il collegamento alla rete Internet. Attraverso questa strada si è inteso privilegiare programmaticamente la capacità di comunicazione delle informazioni e di condivisione di banche dati distribuite: si è ritenuto che questa potesse essere una possibile risposta all'esigenza di integrazione di fonti archivistiche diverse e complesse, quale è appunto l'Archivio storico Iri.

raccoglie ad oggi più di 5.000 reti in 33 nazioni, connette più di 1.500.000 computer e serve circa 6 milioni di utenti.
La disponibilità di software di sviluppo TCP/IP consente di connettere direttamente alla rete Internet calcolatori della dimensione dei PC, dotandoli dei servizi usuali Internet (FTP, Telnet, Ping, IRC) e di sviluppare strumenti per l'accesso a servizi specializzati, come ad esempio WAIS o WWW.
La soluzione studiata per i Consorzi Città Ricerche dal Consorzio Pisa Ricerche consente la connessione di reti locali, LAN PhoneNet e LAN EtherNet, alla rete Internet.
Wide-Area Information Servers è un sistema di accesso a banche dati distribuite ed eterogenee, utilizzato in contesto internazionale.
L'utente che vuole accede ad un server WAIS deve possedere una stazione sulla quale sia installato il software WAIS-client. Questo software è distribuito gratuitamente ed è disponibile in molte piattaforme hardware. Correlativamente la struttura che vuole inserire la propria o le proprie banche dati nel circuito WAIS, deve fare in modo che il proprio sistema diventi un WAIS-server. Ciò avviene implementando uno "strato" software sopra il sistema che gestisce la banca dati, in modo che le richieste di un WAIS-client vengano trasformate in richieste del sistema sottostante. Questo strato software utilizza TCP/IP come veicolo di comunicazione sulla rete fisica, e struttura il contenuto dei messaggi tra servente e cliente secondo le direttive del protocollo standard NISO Z-39-50, originariamente pensato per le interrogazioni ai cataloghi delle biblioteche.
L'interfaccia utente WAIS-client è di immediato apprendimento. Le interrogazioni sono a testo libero e le funzioni di dynamic folder e di relevance feedback consentono rispettivamente di effettuare interrogazioni per passi e di selezionare immediatamente i documenti interessanti tra quelli ottenuti a seguito della interrogazione.

World-Wide Web è un sistema informativo di tipo ipertestuale, che offre un mezzo di navigazione in un ampio universo documentario presente in una rete informativa.
Documenti ipertestuali sono collegati tra di loro attraverso determinati set di parole: WWW può anche includere immagini, grafici, video e suoni. I documenti collegati (linked) possono essere collocati in luoghi diversi della rete.
WWW fornisce una guida specilizzata per accedere a basi dati multimediali distribuite, che adottano un comune formato di descrizione, HTML (HyperText Markup Language) derivato da SGML: il collegamento tra i diversi server è gestito dal protocollo di comunicazione HTTP (HyperText Transfer Protocol).
World-Widw Web adotta un modello client-server ed è disponibile con interfaccia grafica.